

A few weeks back, Cloudera announced CDH 4.1, the latest update release to Cloudera’s Distribution including Apache Hadoop. This is the first release to introduce truly standalone High Availability for the HDFS NameNode, with no dependence on special hardware or external software. This post explains the inner workings of this new feature from a developer’s standpoint. If, instead, you are seeking information on configuring and operating this feature, please refer to the CDH4 High Availability Guide.
Background
Since the beginning of the project, HDFS has been designed around a very simple architecture: a master daemon, called the NameNode, stores filesystem metadata, while slave daemons, called DataNodes, store the filesystem data. The NameNode is highly reliable and efficient, and the simple architecture is what has allowed HDFS to reliably store petabytes of production-critical data in thousands of clusters for many years; however, for quite some time, the NameNode was also a single point of failure (SPOF) for an HDFS cluster. Since the first beta release of CDH4 in February, this issue has been addressed by the introduction of a Standby NameNode, which provides automatic hot failover capability to a backup. For a detailed discussion of the design of the HA NameNode, please refer to the earlier post by my colleague Aaron Myers.
Limitations of NameNode HA in Previous Versions
As described in the March blog post, NameNode High Availability relies on shared storage – in particular, it requires some place in which to store the HDFS edit log which can be written by the Active NameNode, and simultaneously read by the Standby NameNode. In addition, the shared storage must itself be highly available — if it becomes inaccessible, the Active NameNode will no longer be able to continue taking namespace edits.
In versions of HDFS prior to CDH4.1, we required that this shared storage be provided in the form of an NFS mount, typically on an enterprise-grade NAS device. For some organizations, this fit well with their existing operational practices, and indeed we have several customers running highly available NameNode setups in production environments. However, other customers and community members found a number of limitations with the NFS-based storage:
- Custom hardware – the hardware requirements of a NAS device can be expensive. Additionally, fencing configurations may require a remotely controllable Power Distribution Unit (PDU) or other specialized hardware. In addition to the financial expenses, there may be operational costs: many organizations choose not to deploy NAS devices or other custom hardware in their datacenter.
- Complex deployment – even after HDFS is installed, the administrator must take extra steps to configure NFS mounts, custom fencing scripts, etc. This complicates HA deployment and may even cause unavailability if misconfigured.
- Poor NFS client implementations – Many versions of Linux include NFS client implementations that are buggy and difficult to configure. For example, it is easy for an administrator to misconfigure mount options in such a way that the NameNodes will freeze unrecoverably in some outage scenarios.
- External dependencies – depending on a NAS device for storage requires that operators monitor and maintain one more piece of infrastructure. At the minimum, this involves configuring extra alerts and metrics, and in some organizations may also introduce an inter-team dependency: the operations team responsible for storage may be part of a different organizational unit as those responsible for Hadoop Operations.
Removing These Limitations
Given the above limitations and downsides, we evaluated many options and created a short list of requirements for a viable replacement:
- No requirement for special hardware – like the rest of Hadoop, we should depend only on commodity hardware — in particular, on physical nodes that are part of existing clusters.
- No requirement for custom fencing configuration – fencing methods such as STONITH require custom hardware; instead, we should rely only on software methods.
- No SPOFs – since the goal here is HA, we don’t want to simply push the HA requirement onto another component.
Given the requirement to avoid SPOFs and custom hardware, we knew that any design we decided upon would involve storing multiple replicas of the metadata on multiple commodity nodes. Given this, we added the following additional requirements:
- Configurable for any number of failures – rather than designing a system which only tolerates a single failure, we should give operators the flexibility to choose their desired level of resiliency, by adding extra replicas of the metadata.
- One slow replica should not affect latency – because the metadata write path is a critical component for the performance of NameNode operations, we need to ensure that the latency remains low. If we have several replicas, we need to ensure that a failure or slow disk on one of the replicas does not impact the latency of the system.
- Adding journal replicas should not negatively impact latency – if we allow administrators to configure extra replicas to tolerate several simultaneous failures, this should not result in an adverse impact on performance.
As a company focused on making Hadoop easier to deploy and operate, we also considered the following operational requirements:
- Consistency with other Hadoop components– any new components introduced by the design should operate similarly to existing components; for example, they should use XML-based configuration files, log4j logging, and the same metrics framework.
- Operations-focused metrics – since the system is a critical part of NameNode operation, we put a high emphasis on exposing metrics. The new system needs to expose all important metrics so that it can be operated in a long-lived production cluster and give early warnings of any problems — long before they cause unavailability.
- Security – CDH offers comprehensive security, including encryption on the wire and strong authentication via Kerberos. Any new components introduced for the design must uphold the same standards as the rest of the stack: for customers requiring encryption, it is just as important to encrypt metadata as it is to encrypt data.
QuorumJournalManager
After discussion internally at Cloudera, with our customers, and with the community, we designed a system called QuorumJournalManager. This system is based around a simple idea: rather than store the HDFS edit logs in a single location (eg an NFS filer), instead store them on several locations, and use a distributed protocol to ensure that these several locations stay correctly synchronized. In our system, the remote storage is on a new type of HDFS daemon called the JournalNode. The NameNode acts as a client and writes edits to a set of JournalNodes, and considers the edits committed when they have been replicated successfully to a majority of these nodes.
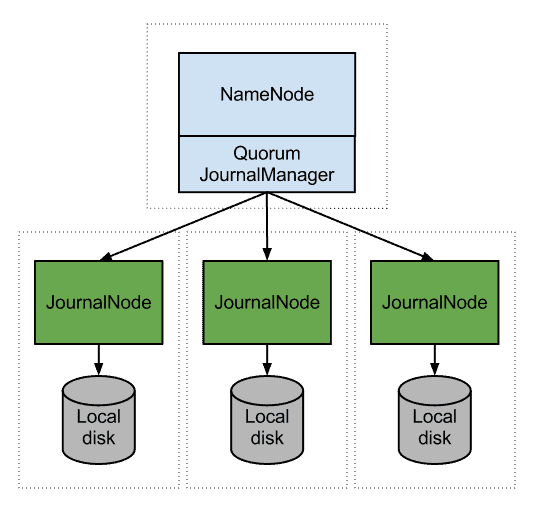
Similarly, when the NameNode in Standby state needs to read the edits to maintain its hot backup of the namespace, it can read from any of the replicas stored on the JournalNodes.
Distributed Commit Protocol
The description above is simplified: the NameNode simply writes edits to each of the three nodes, and succeeds when it is replicated to the majority of them. However, this raises several interesting questions:
- What happens if a batch of edits is sent to one of the nodes but not the others, and then the NameNode crashes?
- What happens if there is a “split brain” scenario in which two NameNodes both try to assert their active (writer) status?
- How does the system recover from inconsistencies at startup, in the case that several nodes crashed while edits were in-flight?
The fully detailed answer to these questions doesn’t fit nicely into a blog post, but short answer is that the system relies upon an implementation of the well-known Paxos protocol. This protocol specifies a correct way of ensuring a consistent value for some piece of data across a cluster of nodes. In our system, we use an implementation of Multi-Paxos to commit each batch of edits, and additionally use Paxos for recovery – the process by which the standby NameNode cleans up any pending batches of edits immediately after a failover. Those interested in the full details and algorithms should reference the HDFS-3077 design document.
Fencing and Epoch Numbers
One of the key requirements for the system, as described in the introduction of this post, is to avoid any special fencing hardware or software. Fencing is the mechanism by which, after a failover, the new Active NameNode ensures that the previous Active is no longer able to make any changes to the system metadata. In other words, fencing is the cure for “Split Brain Syndrome” — a potential scenario in which two nodes both think they are active and make conflicting modifications to the namespace. So, how does the QuorumJournalManager implement fencing?
The key to fencing in the QuorumJournalManager is the concept of epoch numbers. Whenever a NameNode becomes active, it first needs to generate an epoch number. These numbers are integers which strictly increase, and are guaranteed to be unique once assigned. The first active NameNode after the namespace is initialized starts with epoch number 1, and any failovers or restarts result in an increment of the epoch number. In essence, the epoch numbers act as a sequencer between two NameNodes – if a NameNode has a higher epoch number, then it is said to be “newer” then any NameNodes with an earlier epoch number. NameNodes generate these epoch numbers using a simple algorithm which ensures that they are fully unique: a given epoch number will never be assigned twice. The details of this algorithm can also be found in the design document referenced above.
Given two NameNodes, which both think they are active, each with their own unique epoch numbers, how can we avoid Split Brain Syndrome? The answer is suprisingly simple and elegant: when a NameNode sends any message (or remote procedure call) to a JournalNode, it includes its epoch number as part of the request. Whenever the JournalNode receives such a message, it compares the epoch number against a locally stored value called the promised epoch. If the request is coming from a newer epoch, then it records that new epoch as its promised epoch. If instead the request is coming from an older epoch, then it rejects the request. This simple policy avoids split-brain as follows:
- For any NameNode to successfully write edits, it has to successfully write to a majority of nodes. That means that a majority of nodes have to accept its epoch number as the newest.
- When a new NameNode becomes active, it has an epoch number higher than any previous NameNode. So, it simplify makes a call to all of the JournalNodes, causing them to increment their promised epochs. If it succeeds on a majority, it considers the new epoch to be successfully established.
- Because the two majorities above must intersect, it follows that the old NameNode, despite thinking it is active, will no longer be able to make any successful calls to a majority. Hence it is prevented from making any successful namespace modifications.
Testing
Though Paxos is simple on paper, and proven to be correct, it is notoriously difficult to implement correctly. Therefore, while developing this system, we spent more than half of our time on testing and verification. We found a few techniques to be particularly crucial:
- MiniCluster testing – early on, we wrote a simple Java class called MiniJournalCluster, which runs several JournalNodes in the same JVM. This allowed us to automate distributed scenarios in the context of a JUnit functional test case.
- Mock/spy testing – we wrote a number of unit tests using Mockito to inject spies between the QuorumJournalManager client and the JournalNodes within the same JVM. For example, a Mockito spy can easily be instructed to throw an IOException at a function call matching a particular argument. We used this to write deterministic tests for a number of different failure and crash scenarios identified during design discussions.
- Randomized fault testing – although we were able to write tens of tests by hand for different fault scenarios, these tests were limited to the types of failures we could easily mentally generate. In my experience building distributed systems, the ones that are more worrisome are the ones you can’t easily identify a priori. So, we introduced randomized fault tests based on deterministic seeds: given a random seed, the test case introduces a series of faults into the protocol which are completely determined by that seed. For example, a given seed may cause the 2nd, 3rd, 8th, and 45th RPC from the NameNode to the second JournalNode to fail. These tests simulate hundreds of failovers between nodes while injecting faults, and simultaneously verify that no committed transactions are lost.
In addition to running the above tests by traditional means, we also built a test harness to run the randomized fault test on a MapReduce cluster. The test harness is a simple Hadoop Streaming job which runs the randomized fault test for several minutes, then outputs its test log to HDFS. The input to the test is a 5000-line file containing random seeds, and uses an NLineInputFormat to pass each seed to a separate task. Thus, 5000 instances of the random test case can easily be run in parallel on a large cluster. Upon finishing, a second streaming job runs grep against the results, looking either for test failures or for unexpected messages in the log such as AssertionErrors or NullPointerExceptions.
Using this harness, we were able to soak-test millions of failover scenarios and run for several CPU-years, and discovered several bugs along the way. The testing was in fact so comprehensive that we found two new bugs in Jetty, an HTTP Server component used internally by Hadoop. We rolled the fixes for these Jetty bugs into CDH4.1 as well.
Summary
The new feature described in this post is available in CDH4.1 and, thanks to hard work by the Cloudera Manager team, is very easy to deploy and monitor with just a few mouse clicks in CM4.1. Like all of our HDFS development, the project was developed in the open in the Apache Software Foundation repositories and tracked on the ASF JIRA at HDFS-3077 . The new code has been merged into the Apache trunk branch, to be included in an upstream Apache HDFS release in the near future.
Acknowledgements
I would like to acknowledge a number of people from the wider Apache HDFS community who contributed to this project:
- Aaron T. Myers and Eli Collins for code reviews and contributions around security, configuration, and docs
- Sanjay Radia, Suresh Srinivas, Aaron Myers, Eli Collins, Henry Robinson, Patrick Hunt, Ivan Kelly, Andrew Purtell, Flavio Junqueira, Ben Reed, Nicholas Sze, Bikas Saha, and Chao Shi for design discussions
- Brandon Li and Hari Mankude for their work on the HDFS-3092 branch which formed some of the early building blocks for the JournalNode
- Stephen Chu and Andrew Purtell for their help with cluster testing
- Vinithra Varadharajan, Chris Leroy, and the Cloudera Manager team for help with integration testing, metrics and configuration
Editor's Choice


Hi friend,
When talking about “Removing These Limitations”, then how to remove the limitations, like the directory space, 3 journalnodes?
Thanks